
Note from the author...
My posts frequently (like this one) have a 'theme' and tend to use a number of images for visual flourish. Personally, I like it that way, I find it more engaging and I prefer for people to read it that way. However, for users on a metered or slow connection, downloading unnecessary images is, well, unnecessary, potentially costly and kind of rude. Just to be polite to my users, I offer the ability for you to opt out of 'optional' images if the total size of viewing the page would exceed a budget I have currently defined as 200k...
The History and State of Speech
One apocryphal legend says that when the great sculptor Michelangelo carved his statue of Moses, it was so life-like that as he struck his final blow to the left knee he demanded "Now, speak". Sadly, it wasn't that easy. But we've been working hard to figure it out pretty much ever since and, ultimately bring speech to the Web. As often happens, I find myself so interested in understanding how we got here and where we are that it winds up being a whole piece on it's own. So, in this piece I'll tell you about the history and at a high level current state of affairs of Speech on the Web, subsequent posts in this series will be more technical...
The History of Speech Machines
 The Voder machine at the 1939 Worlds fair.
The Voder machine at the 1939 Worlds fair.
At the 1939 World's Fair in New York Bell Labs presented "The Voder" developed by an accoustics engineer named Homer Dudley. It allowed a (very skilled) operator to create human-like voice with inflection. It was pretty impressive and demonstrated that we'd gotten our heads around a lot about generating human voice-like sounds with electronics. It sounded like this
This work continued to evolve and by the early 1960s, Bell Labs was synthesizing speech on an IBM 704 and were able to demo it singing the song Daisy Bell, which inspired Arthur C Clarke's HAL in 2001 A Space Odyssey.
But, like a lot of things at Bell Labs, this was just way way ahead of it's time. The rest of the world just needed to really catch up.
When I was born, to most people, computers were mostly the realm of seemingly far-future science fiction movies. Actual life was pretty analog.
 Here's what my television looked like when I was 4
Here's what my television looked like when I was 4
Back then, you had to get up and walk across the room to change the channel, and you'd do it by physically turning a dial or two and maybe manually moving around an antenna. The year I was born they started selling consoles like Atari Pong. But those were still weird clunky things that you controlled with dials and analog buttons, just like the television.

By the time I was old enough to remember anything, a number of 'toys' were beginning to put together some really interesting things: Texas Instruments had the Speak And Spell released in 1978. The same year, Mego Toy Corp released the 2-XL.
Note all the differences in those two. The 2-XL sounded human, because it was. The Speak and Spell sounded digitized, because it was. Lots of ideas were developing and merging and crashing into one another.
The movie "War Games" introduced me to modems, AI and Text-to-Speech. YEs, his computer... spoke. The idea of networked computers which could actually sort of 'converse' made my head swim. It's probably what ultimately drove me to ask for a computer. Sadly, it didn't talk.
What did get better and better at talking though was games. I won't go through them all, but in 1991 two things occurred. Sega introduced Joe Montana Sports Talk Football which spoke full sentences and announced the game as played. Wow. Also, the Web was born, without much fanfare as a very simple, linkable text thing (and I mean very simple - no styles, no images, forms or buttons, no scripting, no tables even).
Since the Web...
As time went by and computers and software got more and more powerful we continued to chase the dream of making them speak and able to be spoken to.
Dragon Naturally speaking let you 'talk to your computer' in the form of dictation. I was excited enough about this possibility to spend a signifcant fraction of my money buy it in the mid/late 1990s. My limited experience with it went something like this:
This is, of course, a dramatization but it was hillariously short of my dreams - so much so that I pretty much just forgot about speech recognition for a long time after that and threw myself in the Web.
The Web was really taking off and around the time the W3C was formed, plugins like Flash were born and serious standards work began on things like Synchronized Multimedia Integration Language (SMIL) and Virtual Reality Modeling Language.
In 1997, Microsoft introduced Microsoft Agent which would 'read' to you via Text-To-Speech. They even exposed it in their web browser via embeddable objects that you could control with vbScript (as long as you used Microsoft).
With Microsoft having demonstrated it, it seemed very plausbile we might get speech in the browser 'for real' very soon.
In 1998 CSS 2 included Aural Stylesheets. Ever heard of them? They don't work.
In March 1999 AT&T, IBM, Lucent, and Motorola formed the VoiceXML Forum to create a kind of 'HTML, but for speech'. One year later they took VoiceXML to the W3C and a whole bunch of other organizations got involved. Most of them did not make a Web browser.
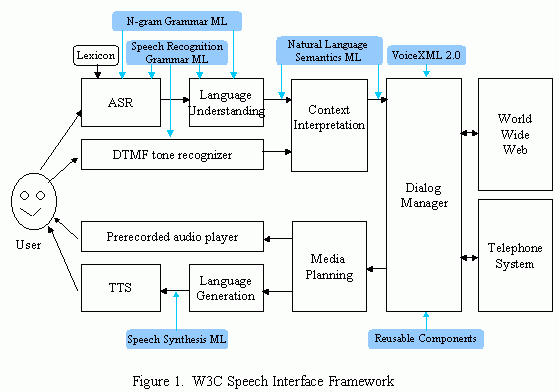
What resulted was not just a codified VoiceXML, but the W3C Speech Interface Framework composed of: Voice XML 2.0, Natural Language Semantics Markup Language, Speech Synthesis Markup Language, Speech Recognition Grammar Markup Language, and N-gram Grammar Markup Language. Ever heard of any of them?
I will pause here while you continue blinking at the screen for a moment.
"The Modern Era"

So, we still didn't have a way in the browser to do this. Then, one day in 2010, a W3C Community Group called the "Speech XG Incubator Group" was started with a developer from Google saying "some of us at google have been working on extending HTML elements for speech". It was right around this time that Siri was introduced to the wider world and a new era of digital assistants began to flourish and evolve.
But, what followed was... mostly boring. It was requirements gathering. Lots of people saying "I think it should X" or "It has to Y" and "No, I disagree because Z". That's... unfortunately how standards in committees work. ,
But quickly, and I mean very quickly Google submitted a proposed draft. Through all of the discussion, they also got a proposal from Mozilla, another from a company called Voxeo and, finally one from Microsoft. It's worth noting that none of these is 'an official proposal' by W3C terms. But, in the end, the result of this Community Group was a Note, effectively, "Here's what we found and what we recommend developing".
The final step here involved whether this work should move now into a real Working Group. But that didn't happen.
What did happen, was the creation of another Community Group led by Google and the statement on April 3, 2012, "Google plans to supply an implementation" of a limited subset of the recommendations of the first group. You see, the requirements and proposals were, like other standards predecessors, very involved and complicated.
Google did, in fact, supply an implementation and wrote an article talking about "HTML5 Speech APIs". This raised some ire because, in fact, it is not part of HTML5, nor was it even on a standards track, it was technically still "just some stuff people were discussing very seriously" in the Community Group.
There were people from smaller orgs, and just general folk - at least one or two people from Microsoft and Mozilla, but the conversation on the mailing-list was really mostly dominated by people working at Google.
In the end though, the product was a Final Report which laid out another API, which is, again not on any standards track.
One might think that the rise in popularity and utility of digital assistants would really spurn the interest in standards bodies to move this forward, but instead it seems to have largely "stalled", which is kind of a shame because the web kind of is the ultimate digital assistant in many respects already... We just have to get it there.
What even is a standard?
Now, when I said it stalled - that doesn't mean nothing has happened. Despite all this history, there are nevertheless, bits of implementation of the unofficial proposal in every modern browser and much of it isn't even behind a flag or prefix!! In fairness, none of them follow it exactly, and to an extent it's hard to say what "it" even is since the spec, out of band errata and implementation shipped by Google don't entirely match. Further, it's kind of wonky even across different OSes for the same browser and whether you're connected to the interwebs or not. It's very much like DOM/CSS support in 1998 or 1999. But, because it's unofficial, addressing issues is typically pretty low priority.
In some sense though, which is the more valuable 'standard' - the unofficial stuff everyone has implemented or the official ones written down that aren't?
I'll explain a lot more details, including gotchas and bits I find problematic in the pieces I set out to write initially. I feel like it is very much in the interest of the Web to work together to drive "this" forward, and by "this" I mean simply let's experiment and figure out what's missing and work get speech into the Web "offically".
Special thanks to my friend, the great Chris Wilson for proofing/commenting on pieces in this series.