
Friendly Fire: The Fog of DOM
Any military is comprised of individuals, grouped into successively larger units. While all of these units are striving for a single overarching goal, they don’t share consciousness and so, regardless of how well trained they are or how much intelligence they have, there is an inevitable amount of uncertainty which is impossible to remove. This concept is sometimes termed “The Fog of War” and one very unfortunate result is that sometimes same-side damage is caused by an ally. This is often referred to as “Friendly Fire” or “Blue on Blue”. In this post, I’ll explain how these same concepts apply in the DOM and talk about how we can avoid danger..
Any large company tends to organize things a bit like a military – individuals in units of units cooperating toward a common goal. If they’re using something like a CMS, one team might define some general layouts for reuse. Another team creating content and still other teams creating reusable/shared ‘widgets’ which are all assembled together (often dynamically) to create a whole page.
One instance of this might look like the figure below:
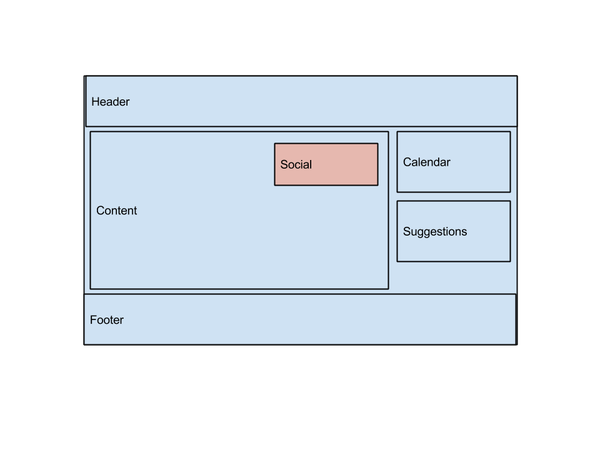
What’s interesting about this is that, at an observable level, only the third-party social sharing buttons are not created and maintained by the company itself and need to be treated as a potentially hostile actor. All of the other pieces are allies in the task of presenting and managing the DOM and any distinction in how they are created, organized and maintained is, at some level, artificial and purely organizational. Anyone who has worked in this sort of model will have experienced “The Fog of DOM“. That is, preventing accidental violence against your allies is really hard – it’s simply too easy to accidentally select and operate on elements that aren’t “yours“. Specifically, it’s not a security concern, it’s a cooperation/coordination concern: The fact that all operate on the same DOM and make use of selectors means that unless there is perfect coordination, even careful use of a selector in a page can easily harm components and vice versa: Friendly fire.
What’s perhaps most surprising is that you don’t actually need a large organization to experience this problem yourself, you just have to want to reuse code that you aren’t developing all at once.
Why is it so damned hard?
Primarily, I think that the answer has a lot to do with how the Web has evolved. First, there was just markup and so this wouldn’t have been much of a problem even if these approaches/large teams existed way back then. Then came JavaScript which had its own default global issues, but at least you could scope your code. Then came real DOM and we could start doing some interesting things. CSS’s aim was to allow you to write rules that allowed you to make broad, sweeping statements like “All paragraphs should have a 1em margin” and then override with more specific statements like “All paragraphs inside a section with the class `suggestions` should have a 2em left margin.” Within the context of what we were doing, this was clearly useful and over time we’ve used selectors to identify elements in JavaScript as well and our projects continued to get bigger, more complex and more ambitious.
Now, while there are some actions I can take to prevent my component from affecting the page that hosts it, it’s incredibly hard to prevent the outer page from accidentally selecting/impacting elements inside components. One mistake on either end could spell problems and since they are maintained separately, by different teams, keeping them constantly in check involves an incredible degree of coordination and in the end any shortcomings in coordination usually mean investigation, hackery and guesswork to resolve.
Note again: This isn’t about security. I’m not concerned that my co-workers could steal my data, it’s their data too. My users are their users, my company is their company. We are allies. It just needs to be plausible for us to easily collaborate and work together toward a common goal without a high chance of hurting our collaborators. It still needs to be possible from the hosting page to say “Yes, I mean all buttons should be blue”, it’s just that it shouldn’t be the only (nor necessarily the default) position because it means it’s impossibly easy to harm your allies.
In short: What the current design means for us, in many cases, is that it’s incredibly hard to “say what you mean” in such a way that it’s likely to avoid the most basic kinds of friendly fire. We have gobs and gobs of selectors stated as document-wide rules which become implausibly hard to reason about. This makes them hard to write and debug. Most sites today have hundreds of selectors, many have thousands – any of which could, theoretically apply in many many permutations. So even if you manage to “get it right” for the time being, when you do have something that suddenly causes unexpected pain (and you will), it’s even more difficult to find out what’s causing it and why because it requires resolving all of those conflicts by resolving the rules in your head without creating others.
Is it “fixable”?
So, is it plausible to imagine a better future? Is it possible to “fix” this problem, or at least make it very markedly better without completely re-inventing things? There have been numerous proposals to do so over the years, all of them failed to gain enough traction to cross the finish line. There were efforts in XBL in the early 2000’s, proposals to allow externally linked CSS mounted/scoped to an element in 2005, and what would become known as “scoped CSS” is discussed and in drafts in 2006. This proposal was actually eventually implemented in Chrome behind a flag and then removed. Removed in part it doesn’t answer all of the questions that another proposal, Shadow DOM did.
We seem to tend to shift back and forth between answers too ambitious or too minimal, and once again, there’s a struggle with agreement. And so, there’s an effort to step back and see if there is something less ambitious but that we actually can get agreement on. Currently there’s a debate about it going on pulling in two possible directions: On one side is a group which posits that this is something that should be handled by CSS, on the other is a group which argues that it shouldn’t. I am in the latter camp, and I’d like to explain why.
Key to both proposals is “isolation” – some kind of boundary at which authors can safely talk and reason about things ‘within a part of a tree’ without implying things outside that part unless they explicitly intend to do so.
OPTION A: “HANDLE IT WITH CSS”
This approach suggests that something, perhaps a new @rule could be used to identify ‘isolation points’ via selectors and that subsequent rules could identify an isolation point for which they were relevant. In fact, however, I believe this creates more questions and problems than it does answers and actually increases the authors’ cognitive load. This raises some interesting follow up questions for me:
- Since selectors operate off the whole document, what if I specify that both .foo and .bar should be isolated (and my rules are in that order), and a .bar occurs inside a .foo?
- Is it isolated as part of the .bar isolation, or only the .foo isolation?
- Imagining I successfully identified an element as being isolated – would rules loaded or specified inside that element (by
link> orstyleorscript) be scoped to that element automatically? - Combine the above to questions and it seems that any answers inevitably create a radically new concept in CSS that affects how selector matching is done. While @rules are indeed ‘different’ by nature, at least historically they don’t seem to raise these kinds of issues. If the new @rule ignores all boundaries to create a new isolation, it does so without any kind of combinator explaining that and it means that the default thing is still sort of an act of violence and you just have to manage avoiding harm through coordination. If it doesn’t then within your ‘component’ (whether it is a true Web Component or not) you have something conceptually very new and it’s possible to ‘lose’ isolation by something as simple as a class change which seems to largely describe the situation we’re in today.
- What about the non-CSS end of things? JavaScript uses selectors too, and has the same kinds of friendly fire issues. With CSS at least I have dev tools to analyze what rules are in play. When I use a selector via querySelectorAll or something will it be context dependent? If it uses the same selector matching as CSS, this is a new kind of problem. It’s never been possible for CSS to affect what kinds of selectors match in DOM, and since it is not reflected in the DOM tree, understanding why this matches or doesn’t requires explanation. If matching works differently in JavaScript, well, that is kind of confusing and leaves an important part of the problem unchanged.
- Would this be readable or writable or deletable through JavaScript? In other words, could JavaScript create an isolation boundary – are we explaining and exposing magic or creating new magic? If they aren’t creatable through JavaScript, it feels like we are going in the wrong direction and even if they aren’t, they’re based on selectors. In other words, there is a backdoor into it because they are very easily mutable. This is either new vector for friendly fire or just a continuation of the one we have depending on how you look at it – either way it seems bad.
- It’s abstract rules. As I said, at a certain point, it becomes incredibly hard to reason about rules and their permutations – especially when they are super mutable as anything defined by selectors would inherently be. The bigger the variance and the more you attempt to break up the work, the harder it is to manage them, and when a problem does happen – how will you debug and understand it?
OPTION B: A NEW DOM CONCEPT
The DOM is built of nodes with parent and child pointers. Pretty much everything about selector matching is already built on this concept. If you can imagine a new kind of Node which simply connected a subtree with links that aren’t parent/child, this is a kind of a game-changer. For purposes here, let’s just call it a “MountNode” to avoid conflation with all the bits of Shadow DOM which is essentially this plus more. Imagine that you’d connect this new MountNode to a hostElement and it would contain a mounted subtree. Instead of the MountNode being just another child of the hostElement then, it is linked through the hostElement’s .mountPoint property instead. And instead of the MountNode having a .parentElement, it has a link back through the .hostElement property. Just something simple like this gets you some interesting effects and offers advantages that none of the other historic approaches (except Shadow DOM) provided:
- Everything that authors understand about trees more or less remains intact, with the slight caveat that there is a new kind of Node (not Element).
- DOM inspectors can show this (see Chrome’s representation of “Shadow Root”) and you can easily explain what’s going on. All of the selector APIs (JavaScript and CSS) work the same way.
- A mount isn’t linked with parent/child nodes so all existing matching schemes work pretty much “as is” without change because they use parent/child traversal.
- Its intuitive then to create a combinator in CSS which allows you to select the mount explicitly because that’s just what combinators do today, tell you what to consider during the tree-walking.
- It’s minimal “new magic”. We don’t create new things where CSS affects DOM, we don’t raise questions about matching or mutability of boundaries – it’s just a new, foundational piece of DOM that in all other respects works just the way it always has and allows us to experiment with and build higher-level answers.
This last point is especially important to me. Is it possible to involve CSS and answer all of the questions in a sane way? To be entirely honest, I don’t know. What I do know, however, is that today this would involve a lot of speculation, decisions and bikeshedding. I think this is better vetted in the community – and that any standards org is just as likely (maybe more) to get it wrong as they are to get it right. Small improvements can have outsized impacts and provide a grounds upon which we can continue to “build” an explainable and layered platform, so I lean toward one that starts low and imperative, with DOM and provides a tool that can be used to solve both the stylistic and imperative ends of it.
What do you think? Share your thoughts at www-style@w3.org.
Many thanks to all my friends who proofread this at some phase of evolution over the past several weeks and helped me (hopefully) give it fair and thoughtful treatment: Chris Wilson, Sylvain Galineau, Brendan Eich, François Remy, Léonie Watson and Coralie Mercier.