
Listen up: Web Speech APIs Part III
This is part of a series about making the browser speak and listen to speech. In my last post You Don't Say: Web Speech APIs Part II, I talked about how I'm personally papering over what we "have" today with regard to making the browser "talk" and why. In this post I'll talk about the other end of that: listening or speech-to-text.
So far we've been talking about the unoffical Web Speech APIs in terms of speech as output, or text-to-speech. As I've said, this is actually supported to some degree in all modern browsers. But now we're going to talk about the other end of things: Speech as input or "voice recognition" or, if you prefer "speech-to-text". This is currently not widely supported - in fact, only Chrome has a "working" implementation popularly deployed, but it is available in FirefoxOS and available behind a flag while they work out some permissions issues and reportedly under development in Edge as well. It's a much harder problem in general, and there are a lot of gotchas here too. In this piece, I'll cover a lot of them.
Let's get started
Ok, so first things first: webkitSpeechRecognition. This is the thing that makes recognition possible. There are a number of really good articles that will tell you that you should have a line that looks something like this:
const SpeechRecognition = window.SpeechRecognition || window.mozSpeechRecognition || window.msSpeechRecognition || window.webkitSpeechRecognition;
const recognition = new SpeechRecognition();
I'm going to recommend, however, that you don't and here's why: Because we're just not far enough along to pretend we know what a compatible and standard SpeechRecognition will look like or that there ever will be any of those others.
This is an approach that used to common, but that has changed and at one point we thought it was a really keen idea. Unfortunately, this interface arrived in Chrome just about the time that we began to admit to ourselves what a problem this creates.
You'll note that nobody likes to ship vendor prefixed stuff anymore in the release channel, and here's part of the reason why: When everyone writes code like the example, it assumes that they aren't experiments or that they must be identical. Purposely,
the original idea was that you could have a webkitThingy and a
msThingy and a mozThingy and those were experimental. That is they might be totally different, competing experiments or simply be used to write tests and practice in order to inform what the real standard would
be. However, in practice, the use of such patterns as the above tended to actually cause that to not be the case at all. There were 'first mover' advantages and 'market share' problems. Once we get even a couple reasonably popular uses of this API,
the experiment now wags the standards dog because there's lots of code depending on it matching things it wasn't intended to. Both ECMA and W3C TAG have had much discussion on this problem.
So, let's just be honest with ourselves and err on the side of caution and say: It's the webkitSpeechRecognition API at this point, and that's all we can say with absolute certainty. If we get truly interoperable implementations, how
hard will it then be to go back and change that one line? Pretty easy, I expect.
Ok so, with this in mind, we could re-write the above as:
const recognition = new webkitSpeechRecognition();
But this is just creating an interface for you, it's not actually doing anything yet.
Events
In order to actually do anything with it, we're going to want to tell this recognizer what we actually want from it via attaching some listeners to it. There are a lot of events that we can plug into, as you will see below but in practice I haven't personally required many of them.
audiostart"Fired when the user agent has started to capture audio."soundstart"Fired when some sound, possibly speech, has been detected."speechstart"Fired when the speech that will be used for speech recognition has started."speechend"Fired when the speech that will be used for speech recognition has ended."soundend"Fired when some sound is no longer detected."audioend"Fired when the user agent has finished capturing audio."result"Fired when the speech recognizer returns a result."nomatchDon't worry about this one for now, we'll come back to it.error"Fired when a speech recognition error occurs."start"Fired when the recognition service has begun to listen to the audio with the intention of recognizing"end"Fired when the service has disconnected"
A few of these are self explanatory in terms of their lifecycle: Starts have to occur before their corresponding ends. However, one could be forgiven for wondering, for example, "which happens first according to these descriptions? audio start or sound start?" To answer your question, let me just quote the spec: Unless specified below, the ordering of the different events is undefined. For example, some implementations may fire audioend before speechstart or speechend if the audio detector is client-side and the speech detector is server-side.
If you're thinking to yourself: "Wow, that seems potentially really confusing and hard to work with," same.
Methods
The recognition object also has 3 methods in charge of whether it is actively listening and feeding things to the above events:
startstopabort
If you're wondering what the difference between stop and abort is, it's actually pretty simple.: Stop means stop listening, but not stop processing and feeding any pending events to its listeners. Abort is a hard disconnect of all the things.
So, at it's most basic: You create a recognizer, add some listeners and call .start() and you should get some results until they are again disconnected (we'll come back to that in a moment)
Starting up
Before we set up an example, it's worth explaining that this feature is "different". Playing some media is something that has been a part of the Web for a really long time, it's not something that requires a special permission. But
listening to your microphone is different, as it should be. That's something that the user has to explicitly give permission for and be made aware when it's happening. As such, when you call .start() Chrome will ask the
user if it's ok for this website to use the mic. Keep in mind, they could well say "no" so you'll want to prepare for that eventuality - it will call the error handler with the event.error property of not-allowed.
Even this, however, is incomplete. "Ok to access the mic" is a pretty 'simple' answer, but it's far reaching. If I want to be able to click a field and speak into it (like Google search on Android), does that mean I am also giving permission to listen to the conversations in the room at all other times as long as there's a tab open? That sounds terrible in most use cases, but there are use cases that are kind of almost that. This is tricky to manage, as you can imagine, so the draft and implementation say that the UA (browser) has to indicate to the user when it is and isn't actually listening and it has to stop when the tab is no longer active. This can take a few different forms, and we'll come back to that - but generally speaking, Chrome on the desktop will (currently) give a user two indicators that distinguish the difference between these two things.
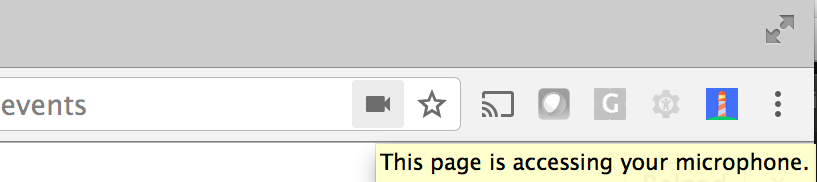 Once the user has given permission, in the right of the address bar, it will say it is accessing the mic. That doesn't mean actively listening for speech.
Once the user has given permission, in the right of the address bar, it will say it is accessing the mic. That doesn't mean actively listening for speech.
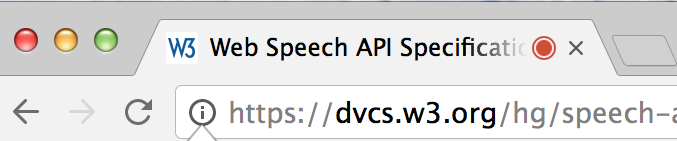 Once we actively start listening, in the tab itself, it will show a red "recording" dot. This dot will disappear when we stop.
Once we actively start listening, in the tab itself, it will show a red "recording" dot. This dot will disappear when we stop.
I personally have trouble believing that the average user will really understand the difference without some training which could happen the first time the mic permission is granted or something, but I've never seen. I'm also not entirely sure how this translates for someone who can't actually see the screen, for example. This is interesting, because that is actually the default assumption on mobile so, on Android it will play audible listening/done listening tones. I'll come back to why this too is currently imperfect, but let's move one.
The most basic example
Alright, so now you know what to expect, as a user and we know basically what the API looks like, let's talk about code.
const recognition = new webkitSpeechRecognition(),
basicExampleOut = document.querySelector('#basicExampleOut')
recognition.onerror = (evt) => {
if (evt.error == 'not-allowed') {
basicExampleOut.innerText =
`I can't listen if you don't grant me permission :(`
} else {
basicExampleOut.innerText =
`Whoops I got an ${evt.error} error`
}
}
recognition.onresult = (evt) => {
// What is this crazy thing?! Don't worry, we'll get to it.
let whatIHeard = evt.results[0][0].transcript
basicExampleOut.innerText = whatIHeard
}
recognition.start()
Note that once you got a result, it stopped listening for more results automatically. By default, this is how it works. Now let's talk about that crazy evt.results[0][0].transcript thing.
evt.results
evt.results is, as you might have guessed a collection. Unfortunately, it is not a true Array (very sadly since other things in the TTS portions covered in previous articles are) but another weird array-like thing called
a SpeechRecognitionResults. By default, it will have exactly one item. It contains, in turn, individial SpeechRecognitionResult objects.
So just what is a SpeechRecognitionResult? By default, its basically also an array-like with just one item called a SpeechRecognitionAlternative. Wait what? I know, it seems weird, but stick with me...
SpeechRecognitionAlternative is really the 'thing' that you want and .transcript is the text it transcribed from what it heard on the mic. This object also has property called confidence which is a numeric
value between 0 and 1 representing how confident the recogntion system is that it got that right.
recognition.onresult = (evt) => {
// evt.results is an array-like collection of
// SpeechRecognitionResult objects
let speecRecognitionResults = evt.results,
// it's a collection of exactly one by default (see below),
// but that is also array-like
speechReognitionAlternatives = speechRecognitionResults[0]
// but that also contains by default exactly one
alternative = speechRecognitionAlternatives[0]
// and _that_ thing has all the properties
console.log(alternative.transcript)
}
You are undoubtedly thinking "Wow, why all the complexity?!" To understand this, you need to note that several times above I said "by default". That's because the draft also provides for other use cases and we really need go no further than this next property/example to see why..
Max Alternatives
The recognizer we set up has a property called maxAlternatives which is a numeric value indicating how many alternatives we're willing to receive. Let's take the following example:
var recog = new webkitSpeechRecognition()
recog.maxAlternatives = 10
recog.onerror = (evt) => {
debugger
}
recog.onresult = (evt) => {
let alternatives = Array.from(evt.results[0])
alternatives.forEach((result) => {
console.log(
`
confidence: ${result.confidence}
transcript: "${result.transcript}"
`)
})
}
recog.start()
If I run this in Chrome, on my desktop mac, and then say "Tutu" it will log something like this:
confidence: 0.7706348896026611
transcript: "tutu"
confidence: 0.9056409001350403
transcript: "two two"
confidence: 0.9139654040336609
transcript: "to to"
confidence: 0.9311671257019043
transcript: "2 2"
confidence: 0.933784008026123
transcript: "- 2"
confidence: 0.9352703094482422
transcript: "too too"
confidence: 0.9483599662780762
transcript: "22"
confidence: 0.9183915853500366
transcript: "TuTiTu"
confidence: 0.9120156168937683
transcript: "to 2"
confidence: 0.9352703094482422
transcript: "tu tu"If, however, I run the same code and say "Desmond Tutu", I get only a single result:
confidence: 0.9614496827125549
transcript: "Desmond Tutu"So, as you can see, speech can be ambiguous and depending on the quality of the implementation of the thing transcribing speech and the amount of context you hand them, the quality of the mic and the voice/pronounciation/accent of the speaker, they may be able to, or want to give you alternatives if they can't be very sure. And - well - if you're into that sort of thing and prepared to deal with that yourself, that's pretty cool.
Ok, but what about that SpeechRecognitionResults thing... Why is that an array-like?? Why do we still grab the first one in that last example? Hang in there...
.continuous
The recognizer you create also has a .continuous property which, by default is false. The idea is that there are use cases (like dictation) in which once the user has indicated that they want the program to start listening, we do not actually want it to stop (or miss anything) until it's told to. That's "continuous mode".
If the "continuous mode" flag is set then evt.results will have one more item each time and you'll want the evt.results[evt.results.length-1] to get 'this one'.
Chrome on the desktop's implementation is buggy and shows it still recording after page refresh despite the fact that you have no way to now tell it to stop or to get the results it's grabbing anymore. Basically, you have to kill the tab to get it to stop as far as I can tell, which seems awful.
Firefox doesn't support this. They say you can have the handling of one result just start listening again. That is indeed much simpler, probably much easier on the memory and very nearly approximate - except on mobile where start/stop listening is accompanied by audible tones.
"Other" bits
SpeechRecognition (the recognizer object you create) has some 'other bits' too...
There's a .lang property. Like speech, it defaults to the document language and can be a string representing a BCP 47 language tag (like en-US) which changes the dictionaries it's recognizing against. So, setting it to it, will make it recognize Italian, but not English or Japanese.
As it was with utterances, setting this to something invalid, like for example, "Pittsburghese" will simply cause it to use the default.
There's a .serviceURI property which is supposed to let you
choose which recognition service to use if not the default one.
In theory, being a URI it can be either a
local service or a remote URL.
In theory, it would also "work" - but it seems to be ignored entirely in Chrome and so I see little point in saying much more about it here.
There's a .grammars property which is another array-like called a SpeechGrammarList with two methods for modifying it: .addFromURI(in DOMString src,
optional float weight) and .addFromString(in DOMString string,
optional float weight). The idea here is to allow you to express
domain specific grammars as a kind of weighted rule-set.
As near as I can tell, here's what the draft as to say about what grammars are supported: shrug. You'll see some examples (for example on MDN) that show these using, for example, JSGF (Java Speech Grammar Format). Note, that's not really a 'standard' as far as I can tell either, there's a W3C note about it. In any case, it's unspecified currently how it will work without a grammar or entirely how those should work and in practice in Chrome I was unable to find any difference at all whether you set it or not, so again, little point in saying more about it here and now beyond that.
Wrapping up
So, it's interesting. It works experimentally, if you can use only the parts that work. It isn't nearly as far along 'in practice' as the text-to-speech APIs and even the limited implementations we have have some wonky bits... In my next post, I'll talk about how I am dealing with the wonky bits of this, and putting together some interesting things you can do with it.
Special thanks to my friend, the great Chris Wilson for proofing/commenting on pieces in this series.